

 Meta, OpenAI tarafından geliştirilen ChatGPT başta olmak üzere diğer modern sohbet robotları gibi uygulamaları yönlendirmek için tasarlanmış yeni bir yapay zeka modeli ailesi olan Llama 2’yi duyurdu. Halka açık verilerin bir karışımı üzerinde eğitilen Meta, Llama 2’nin performansının önceki nesil Llama modellerine göre önemli ölçüde arttığını iddia ediyor. Llama 2’nin alametifarikası diğer modellerden daha güvenli olması gibi duruyor.
Meta, OpenAI tarafından geliştirilen ChatGPT başta olmak üzere diğer modern sohbet robotları gibi uygulamaları yönlendirmek için tasarlanmış yeni bir yapay zeka modeli ailesi olan Llama 2’yi duyurdu. Halka açık verilerin bir karışımı üzerinde eğitilen Meta, Llama 2’nin performansının önceki nesil Llama modellerine göre önemli ölçüde arttığını iddia ediyor. Llama 2’nin alametifarikası diğer modellerden daha güvenli olması gibi duruyor. Llama 2, ticari kullanıma sunuldu
 Llama 2, diğer chatbot benzeri sistemlerle karşılaştırılabilecek şekilde, komutlara yanıt olarak metin ve kod üretebilen bir modeller koleksiyonu olan Llama’nın devamı niteliğinde. Ancak isteyen herkes Llama modelini kullanamıyordu. Meta, kötüye kullanım korkusuyla modellere erişimi engellemeye karar vermişti ancak model daha sonra bir şekilde internete sızdırılmıştı. Buna karşılık Llama 2, araştırma ve ticari kullanım için ücretsiz olacak.
Llama 2, diğer chatbot benzeri sistemlerle karşılaştırılabilecek şekilde, komutlara yanıt olarak metin ve kod üretebilen bir modeller koleksiyonu olan Llama’nın devamı niteliğinde. Ancak isteyen herkes Llama modelini kullanamıyordu. Meta, kötüye kullanım korkusuyla modellere erişimi engellemeye karar vermişti ancak model daha sonra bir şekilde internete sızdırılmıştı. Buna karşılık Llama 2, araştırma ve ticari kullanım için ücretsiz olacak. Meta, Llama 2’nin Microsoft ile genişletilmiş bir ortaklık sayesinde Windows‘un yanı sıra Qualcomm’un Snapdragon yongalarını barındıran akıllı telefonlar ve PC’ler için optimize edildiğini ve çalıştırılmasının daha kolay olacağını söylüyor. (Qualcomm, Llama 2’yi 2024 yılında Snapdragon cihazlarına getirmek için çalıştığını söylüyor).
Llama 2’nin Llama’dan farkı nedir?
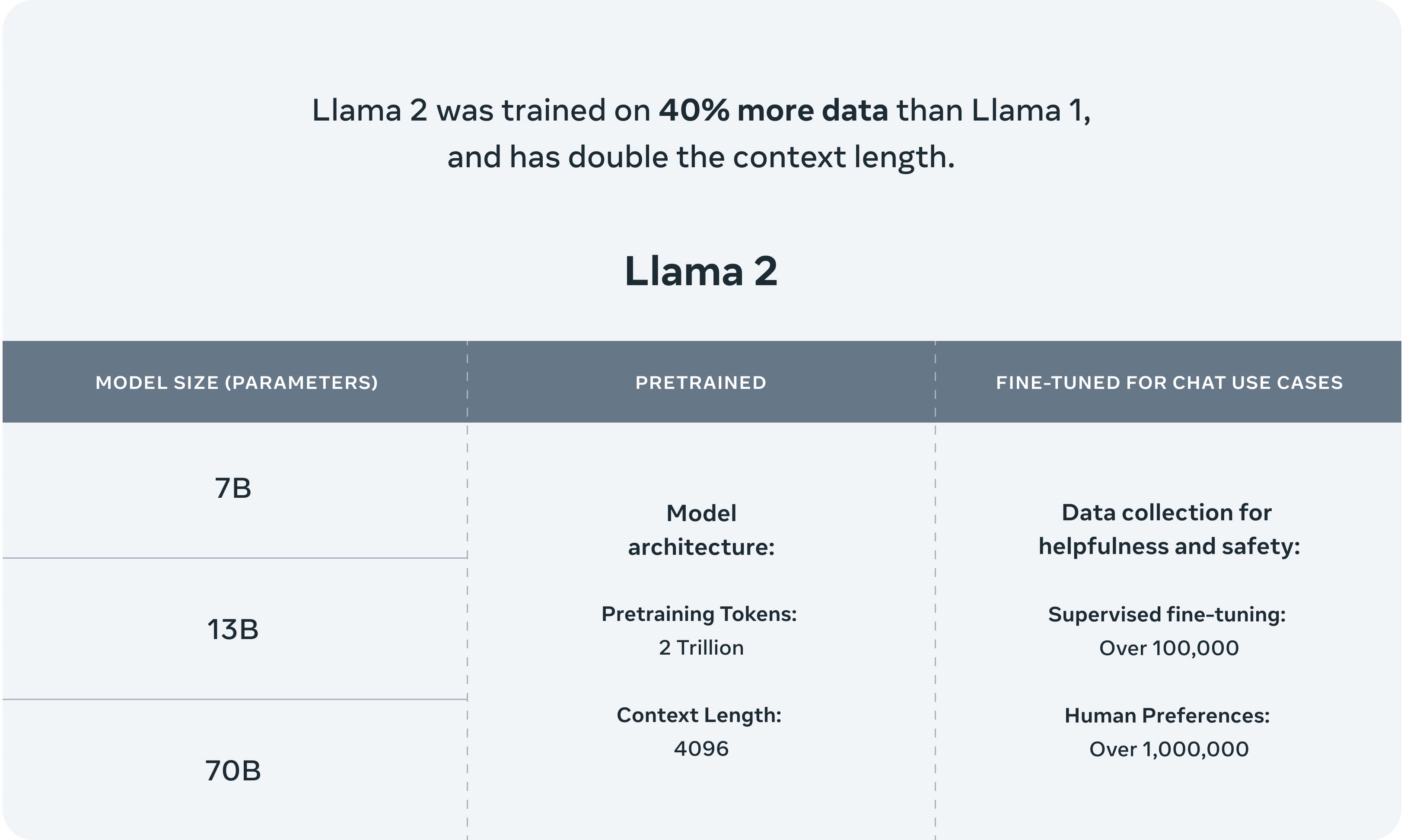
 Llama 2’nin Llama 2 ve Llama 2-Chat olmak üzere iki çeşidi bulunuyor; bunlardan ikincisi iki yönlü konuşmalar için hassas bir şekilde ayarlanmış ve optimize edilmiş. Llama 2 ve Llama 2-Chat, farklı karmaşıklıktaki versiyonlara ayrılmış olarak geliyor: 7 milyar parametre, 13 milyar parametre ve 70 milyar parametre.
Llama 2’nin Llama 2 ve Llama 2-Chat olmak üzere iki çeşidi bulunuyor; bunlardan ikincisi iki yönlü konuşmalar için hassas bir şekilde ayarlanmış ve optimize edilmiş. Llama 2 ve Llama 2-Chat, farklı karmaşıklıktaki versiyonlara ayrılmış olarak geliyor: 7 milyar parametre, 13 milyar parametre ve 70 milyar parametre. Llama 2 aynı zamanda iki trilyon belirteç üzerine eğitildi, burada “belirteçler” ham metni temsil ediyor. Bu sayı, Llama’nın eğitildiği sayının (1,4 trilyon) neredeyse iki katı kadar ve genel olarak konuşmak gerekirse, yapay zeka söz konusu olduğunda ne kadar çok belirteç olursa o kadar iyi. Bu arada Google’ın mevcut amiral gemisi olan büyük dil modeli (LLM) PaLM 2‘nin 3,6 trilyon belirteç üzerinde eğitildiği bildiriliyor ve OpenAI’ın GPT-4 modelinin ise trilyonlarca belirteç üzerinde eğitildiği tahmin ediliyor.
 Meta, Llama 2’nin eğitim verilerinin spesifik kaynaklarını açıklamıyor. Firma bunların web’den, çoğunlukla İngilizce olarak toplandığını ancak şirketin kendi ürünlerinden veya hizmetlerinden olmadığını ve “olgusal” nitelikte bir metni vurguladıklarını belirtiyor. Açıkçası yapay zeka söz konusu olduğunda “eğitim verisinin” açıklanmamasının en temel nedeni yasal tartışmalar diyebiliriz, zira büyük bir telif mücadelesi olacak gibi görünüyor.
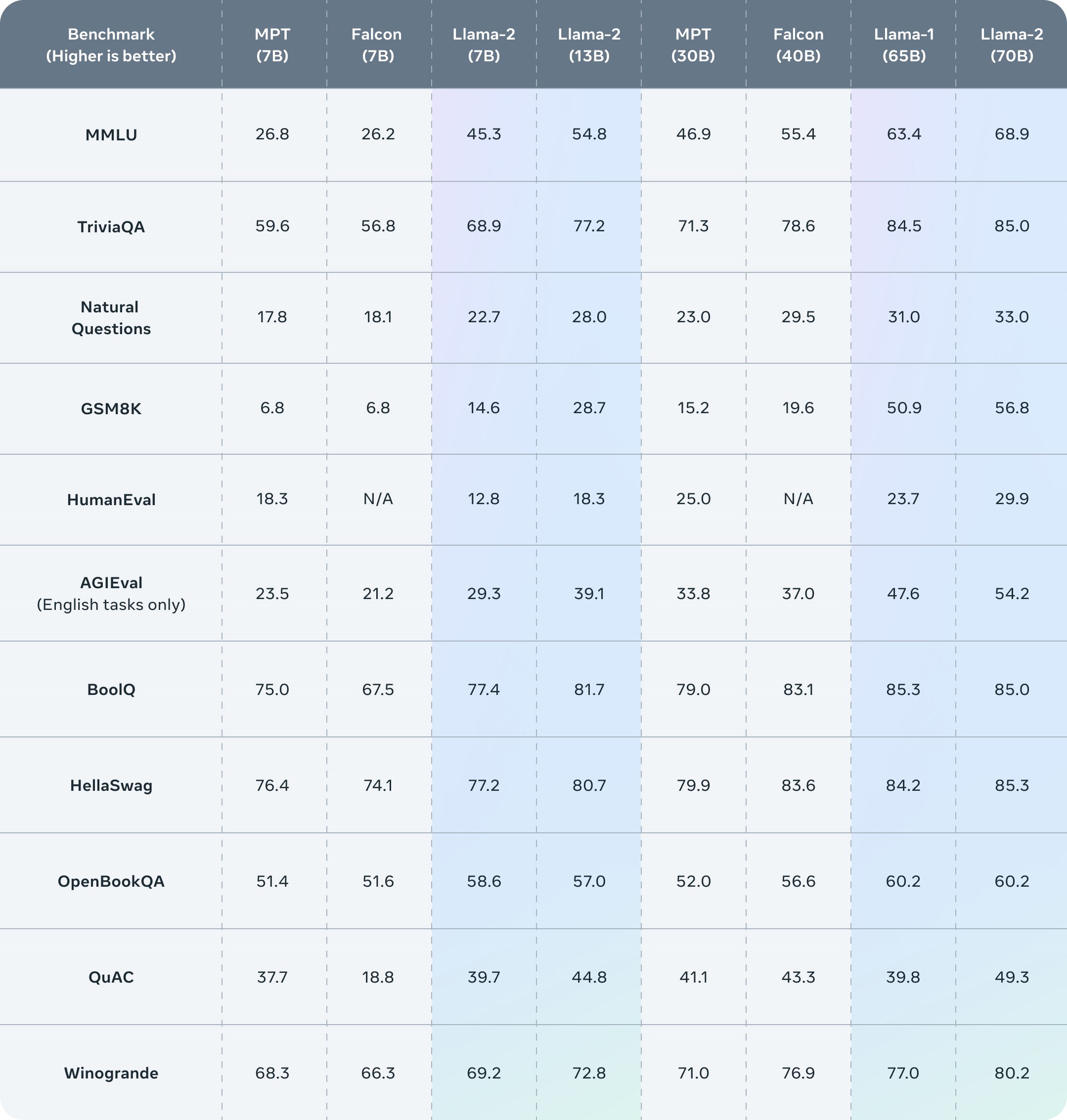
Meta, Llama 2’nin eğitim verilerinin spesifik kaynaklarını açıklamıyor. Firma bunların web’den, çoğunlukla İngilizce olarak toplandığını ancak şirketin kendi ürünlerinden veya hizmetlerinden olmadığını ve “olgusal” nitelikte bir metni vurguladıklarını belirtiyor. Açıkçası yapay zeka söz konusu olduğunda “eğitim verisinin” açıklanmamasının en temel nedeni yasal tartışmalar diyebiliriz, zira büyük bir telif mücadelesi olacak gibi görünüyor. 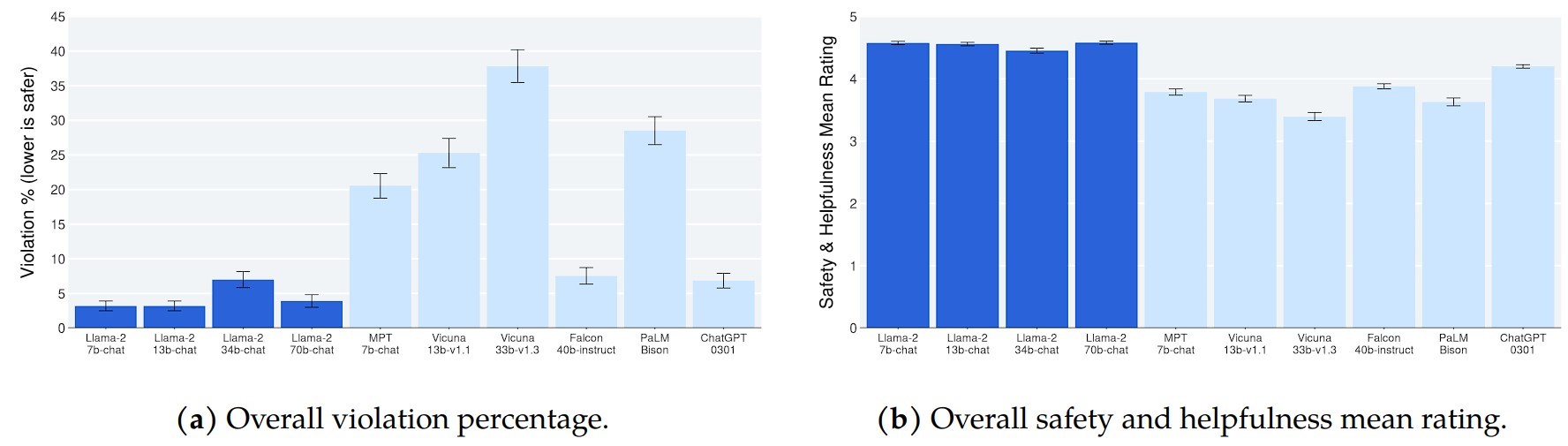 Konuya dönecek olursak Meta, Llama 2 modellerinin en büyük rakipleri olan GPT-4 ve PaLM 2’den biraz daha kötü performans gösterdiğini ve Llama 2’nin bilgisayar programlamada GPT-4’ün önemli ölçüde gerisinde kaldığını söylüyor. Ancak Meta, insan değerlendiricilerin Llama 2’yi kabaca ChatGPT kadar “yararlı” bulduğunu iddia ediyor
Konuya dönecek olursak Meta, Llama 2 modellerinin en büyük rakipleri olan GPT-4 ve PaLM 2’den biraz daha kötü performans gösterdiğini ve Llama 2’nin bilgisayar programlamada GPT-4’ün önemli ölçüde gerisinde kaldığını söylüyor. Ancak Meta, insan değerlendiricilerin Llama 2’yi kabaca ChatGPT kadar “yararlı” bulduğunu iddia ediyor Meta ayrıca Llama 2’nin, tüm üretken yapay zeka modelleri gibi, belirli eksenlerde önyargılara sahip olduğunu kabul ediyor. Örneğin Llama 2, eğitim verilerindeki dengesizlikler nedeniyle “erkek” zamirlerini “kadın” zamirlerinden daha yüksek oranda üretmeye meyilli. Eğitim verilerindeki toksik metinlerin bir sonucu olarak, toksisite kıyaslamalarında diğer modellerden daha iyi performans göstermiyor.
Son olarak, açık kaynak modellerinin doğası gereği, modellerin tam olarak nasıl ya da nerede kullanılacağını söylemek mümkün değil. İnternetin yıldırım hızıyla hareket ettiği düşünülürse, bunu öğrenmemiz çok uzun sürmeyecektir.
Bir yanıt bırakın